
Digital Elevation Models (DEM) vs. Digital Surface Models (DSM)
Nuances and Applications

Digital Elevation Models (DEMs) and Digital Surface Models (DSMs) are both valuable tools in geospatial analysis, yet they serve distinct purposes. DEMs represent the bare earth terrain, providing elevation data devoid of surface features such as buildings and vegetation. In contrast, DSMs capture the complete surface, including natural and anthropogenic features. Understanding the differences between these models is essential for effective terrain analysis, environmental assessment, and infrastructure planning. In this article, we explore the characteristics of DEMs and DSMs, highlighting their respective applications and implications for geospatial research and analysis.
What is a DEM?
A Digital Elevation Model (DEM) is essentially a 3D representation of a terrain's surface created from terrain elevation data. Imagine taking a bird's eye view of a landscape and being able to measure the height of the ground at various points. A DEM gives you a detailed map of these height measurements, offering insights into the topography of the land. It's like having a mold of the Earth's surface, but in a digital gridded form.
And a DSM?
A Digital Surface Model (DSM), on the other hand, includes all-terrain features along with vegetation, buildings, and other objects on the earth's surface. If a DEM shows you the bare earth, a DSM reveals the earth dressed up with its natural and man-made features. It's like taking a snapshot from above that captures not just the ground but everything standing on it.
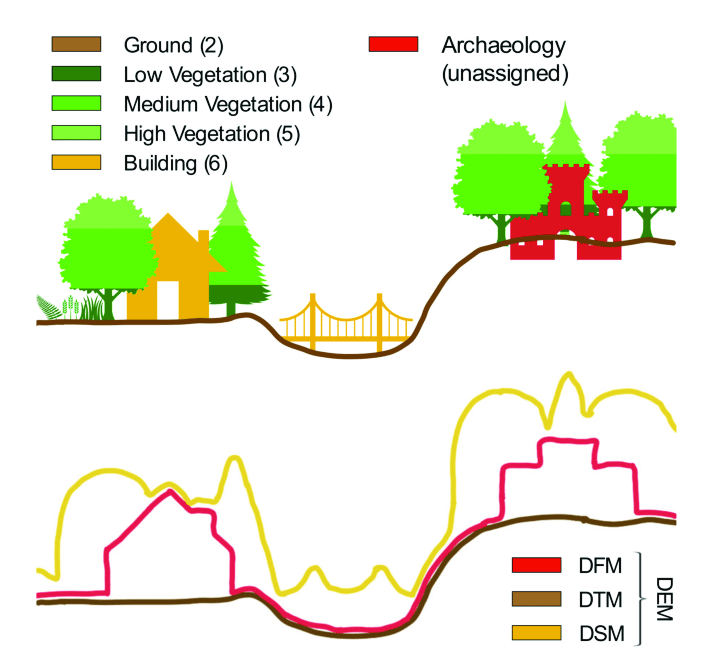
Comparison diagram illustrating the distinction between Digital Surface Model (DSM) and Digital Elevation Model (DEM), highlighting how DSM captures all surface features including buildings and vegetation, while DEM represents bare earth elevation, crucial for terrain analysis and engineering applications (Štular et al., 2021)
The Key Differences
Terrain vs. Surface: DEMs focus on the bare earth's terrain, while DSMs include buildings, vegetation, and other features on the earth's surface.
Use Cases: DEMs are crucial for understanding geological features, flood modeling, and land use planning. DSMs are vital for urban planning, line of sight analysis, and in applications like solar panel placements where you need to consider the height and presence of surrounding objects.
Visualizing the Process: Gridding Unordered Points
Now, imagine we have a scattered collection of points, each with its own elevation value, scattered like stars in the sky. Our goal is to transform this chaos into a structured grid, where each grid cell represents an area of the terrain with a specific elevation. This process is crucial for creating DEMs and DSMs from raw data collected via surveys or remote sensing technologies.
Why Gridding?
Gridding data points from technologies like LiDAR (Light Detection and Ranging) helps make sense of the world in a way that's both accessible and useful for everyone. Imagine LiDAR as a high-tech camera that takes pictures not with light, but with lasers. These lasers bounce back from the ground, buildings, and trees, creating a cloud of points that shows us the shape of everything it hits. However, this "cloud" is messy and hard to understand at first glance because it's just a huge collection of dots with no clear order. That’s where gridding comes into play! Gridding involves binning
Gridding in the context of LiDAR or similar point cloud data involves organizing these unordered, three-dimensional points into a structured, two-dimensional grid format. Each grid cell, or pixel, represents a specific area on the ground, with a spatial resolution that could be as detailed as a few centimeters to several meters, depending on the application and the precision of the data collection method. This process is crucial for transforming the raw, spatially dense point clouds into a manageable, analyzable form.
The challenge with gridding LiDAR data lies in how to accurately represent the surface within each grid cell given that multiple points, each with potentially varying elevations, may fall within a single cell's area. To address this, several interpolation or binning techniques are employed:
1. Simple Averaging: Averaging the elevation values of all points within a cell. This method is straightforward but can be influenced by outliers or non-ground points (e.g., vegetation, buildings).
2. Highest or Lowest Point: Selecting either the highest or lowest point within each grid cell to represent features like canopy height or ground level. This choice depends on the intended use of the grid (e.g., creating a Digital Surface Model vs. a Digital Terrain Model).
3. Interpolation Methods: Techniques such as Nearest Neighbor, Inverse Distance Weighted (IDW), or more complex statistical methods like Kriging. These methods estimate the cell's value based on the surrounding points' values and distances, aiming to create a smoother and more accurate representation of the surface.
The goal of gridding is to condense the rich detail and high dimensionality of point cloud data into a format that's easier to work with for various applications, from environmental monitoring and urban planning to archaeology and disaster management. The spatial resolution of the grid determines the level of detail and scale at which analyses and visualizations can be performed, balancing the need for precision with the practicalities of data storage and processing capabilities.
Ultimately, the interpolated grid becomes a digital reflection of the Earth's surface, a tool for analysis, decision-making, and visualization. Whether it's used to guide the construction of a new building, monitor changes in forest cover, or create a virtual reality experience, the quality of the interpolation directly impacts the utility and reliability of the resulting model. By carefully preserving the information contained in the raw data, we unlock the full potential of technologies like LiDAR, bridging the gap between the digital and the tangible, and enhancing our ability to understand and interact with the world around us.
Python Implementation: Creating a DEM/DSM
Let's embark on a coding journey to create our own simple DEM using two popular interpolation methods: Nearest Neighbor and Inverse Distance Weighting (IDW). These methods help us estimate elevation values for grid points based on the scattered points we have.
Certainly! Nearest Neighbor Interpolation and Inverse Distance Weighting (IDW) are two common methods for interpolating spatial data, such as elevations from LiDAR data. Let's delve deeper into these methods and introduce Kriging, another sophisticated interpolation technique.
Nearest Neighbor Interpolation
As previously mentioned, Nnarest-neighbor interpolation is a simple and intuitive method. For each grid point where you want to estimate a value (such as elevation), you locate the nearest sample point and adopt its value for the grid point. This method is quick and easy to implement, making it appealing for applications where speed is more critical than precision. However, it can result in a "blocky" or "stepped" appearance in the interpolated surface because it does not consider the values of other nearby points, leading to abrupt changes in elevation between grid cells. However, it can be implemented in such a way as to guarantee O(nlog(n)) complexity with a KDTree implementation making it appealing for use cases demanding high computation speed and low resources over highly accurate surface representation.

This diagram illustrates the concept of nearest-neighbor interpolation within a structured grid. Each cell within the grid represents a specific spatial resolution, with the x resolution indicated horizontally and the y resolution indicated vertically. The blue dots represent unordered data points — for example, elevation data points from a LiDAR scan. The red point symbolizes an interpolated data point located at the center of the grid cell. The black line connects this interpolated point to its nearest data point, indicating that the value of the nearest true data point (blue) is assigned to the grid cell. This is a visual representation of how spatial data is organized and interpolated to transform raw, unstructured information into a usable and structured format
Inverse Distance Weighted
IDW takes a more refined approach by considering the distances of multiple nearby points to estimate the value of a grid point. The basic premise is that points closer to the grid point in question have a greater influence on its value than points further away. This method typically involves a "power" parameter that determines how quickly the influence of a point decreases with distance. A higher power results in a more localized interpolation, where the nearest points have a much greater influence, potentially leading to a more varied surface that better captures local variations in the data.

Kriging
Kriging is a more advanced statistical method that not only considers the distance between points but also the spatial correlation among the points to estimate values at unknown locations. It is based on the principle that spatially closer points are likely to have similar values. However, unlike IDW, Kriging uses a model of spatial variance (known as the semivariogram) to weigh the points according to both distance and the observed variability in the dataset.
Kriging is often preferred for its ability to provide not just an estimate but also a measure of uncertainty or variance for each interpolated value. This aspect is particularly valuable in scientific research and resource exploration, where understanding the confidence in data predictions is crucial. Kriging can be significantly more computationally intensive than Nearest Neighbor or IDW (approaching O(n^2)). This complexity arises because Kriging involves constructing and inverting a covariance matrix that reflects the spatial autocorrelation among all pairs of points in the dataset. However, its ability to produce a statistically optimal estimate—taking into account the spatial structure of the data—makes it a powerful tool for creating detailed and accurate spatial models.

This image showcases the fundamental components of a semivariogram used in kriging interpolation. At the core of the graph is the semivariogram curve, which represents how spatial autocorrelation varies with distance between sample points. Key features include the "nugget," indicating measurement error or spatial variability at very short distances, and the "sill," representing the point at which the increase in variance with distance levels off, meaning beyond this range there is no spatial autocorrelation. The distance at which the curve first flattens out is known as the "range," beyond which points do not influence each other. Together, these elements are critical in determining the weights for kriging, allowing for spatial predictions with minimized variance (Rahman et al., 2020)
Each of these interpolation methods has its advantages and is best suited to different types of data and analysis requirements. Nearest Neighbor is best for quick, rough estimates; IDW is useful for a balance between simplicity and capturing local detail; and Kriging offers the highest level of detail and accuracy, especially in datasets with complex spatial relationships. See this great lecture from the University Of Texas Geoscience Department. I also highly recommend watching the whole series as the speaker gives a great rundown on geostatistics!
Nearest Neighbor Implementation In Python
For demonstration purposes, we'll manually define a small set of LiDAR data points as our "known points." In a real-world application, you would retrieve this data via the 3DEP API or other LiDAR data sources.
import numpy as np
from scipy.spatial import KDTree
# Simulated LiDAR data points (x, y, elevation)
known_points = np.array([
[10, 10, 100], # Example point with x=10, y=10, elevation=100
[20, 20, 200],
[30, 30, 300],
# Add more points as needed
])Defining Spatial Resolution and Creating a Mesh Grid
Next, let's define our spatial resolution and create the mesh grid where we'll interpolate the elevation values.
# Spatial resolution (in meters)
spatial_resolution = 0.5 # e.g., 0.5x0.5 meters per pixel for a finer resolution
# Define the extent of the area covered by the LiDAR data
xmin, xmax = 0, 40
ymin, ymax = 0, 40
# Calculate the dimensions of the mesh grid
x_pixels = int((xmax - xmin) / spatial_resolution) + 1
y_pixels = int((ymax - ymin) / spatial_resolution) + 1
# Generate mesh grid coordinates
x_coordinates = np.linspace(xmin, xmax, x_pixels)
y_coordinates = np.linspace(ymin, ymax, y_pixels)
xmesh, ymesh = np.meshgrid(x_coordinates, y_coordinates)
Performing Nearest Neighbor Interpolation Using a KDTree
With our "known points" and mesh grid prepared, we can now interpolate the elevation data.
# Create the KDTree using known points (x, y coordinates only)
xy_known_points = known_points[:, :2]
tree = KDTree(xy_known_points)
# Flatten the mesh grid for querying with the KDTree
query_points = np.column_stack([xmesh.ravel(), ymesh.ravel()])
# Find the nearest known point for each query point
distances, indices = tree.query(query_points)
# Continue from the previous KDTree setup
# Initialize the elevation grid with zeros
elevation_grid = np.zeros_like(xmesh)
# Flatten the xmesh and ymesh for KDTree queries
query_points = np.column_stack([xmesh.ravel(), ymesh.ravel()])
# Perform the KDTree query
distances, indices = tree.query(query_points)
# Now, correctly assign the elevation of the nearest neighbor to each point in the elevation_grid
# Iterate through the grid indices to map elevations
for idx, elevation_index in enumerate(indices):
elevation_grid.ravel()[idx] = known_points[elevation_index, 2]
# Reshape elevation_grid back to the original mesh grid shape, if needed
elevation_grid = elevation_grid.reshape(xmesh.shape)
Explanation
Initialization: create a
elevation_gridfilled with zeros that match the dimensions of yourxmeshandymesh. This grid will eventually hold the interpolated elevation values.Querying KDTree: You flatten
xmeshandymeshto create a list of query points, which you then use to find the nearest known elevation point for each grid location via the KDTree.Assigning Elevations: For each point in your query, you use the index of the nearest known point (
indicesfrom the KDTree query) to look up the corresponding elevation inknown_points. You then assign this elevation value to the appropriate position inelevation_grid.
IDW Implementation In Python
import numpy as np
# Known points (x, y, elevation)
known_points = np.array([
[10, 10, 100],
[20, 20, 200],
[30, 30, 300]
])
# Define spatial resolution and grid dimensions
spatial_resolution = 0.5 # meters
xmin, xmax, ymin, ymax = 0, 40, 0, 40
x_pixels = int((xmax - xmin) / spatial_resolution) + 1
y_pixels = int((ymax - ymin) / spatial_resolution) + 1
# Generate the mesh grid
x_coordinates = np.linspace(xmin, xmax, x_pixels)
y_coordinates = np.linspace(ymin, ymax, y_pixels)
xmesh, ymesh = np.meshgrid(x_coordinates, y_coordinates)
Next, we define our IDW function
def idw_interpolation(x, y, known_points, power=2):
# Initialize the output array with zeros
interpolated_values = np.zeros(x.shape)
for i in range(x.shape[0]):
for j in range(x.shape[1]):
# Calculate the distances from the current grid point to all known points
distances = np.sqrt((x[i, j] - known_points[:, 0])**2 + (y[i, j] - known_points[:, 1])**2)
# Prevent division by zero for points exactly at known locations
distances = np.where(distances == 0, 1e-12, distances)
# Calculate the weights using the inverse of the distance to the power
weights = 1 / distances**power
# Calculate the weighted average elevation
interpolated_values[i, j] = np.sum(weights * known_points[:, 2]) / np.sum(weights)
return interpolated_values
# Perform IDW interpolation across the mesh grid
elevation_grid = idw_interpolation(xmesh, ymesh, known_points)
Explanation
Initialization: We create a mesh grid based on the defined spatial resolution, which will cover the area of interest for elevation interpolation.
IDW Interpolation: For each point on the mesh grid, distances to all known points are calculated. These distances are then used to compute weights for a weighted average calculation of elevation. The ‘power’ parameter controls how quickly the influence of distant points decreases; a common choice is 2, meaning influence decreases with the square of the distance.
Assigning Elevations: The weighted average elevation is calculated for each grid point, producing a continuous surface of elevation values across the mesh grid. This surface is based on the spatial variability and distribution of the known points, taking into account the distances to influence the interpolation outcome.
Kriging Implementation In Python
For this implementation, we will leverage an existing kriging PyKrige
from pykrige.ok import OrdinaryKriging
import matplotlib.pyplot as plt
# Extract x, y, and z (elevation) components from known_points
x_known, y_known, z_known = known_points[:, 0], known_points[:, 1], known_points[:, 2]
# Create an Ordinary Kriging object with known points
OK = OrdinaryKriging(x_known, y_known, z_known, variogram_model='linear')
# Perform Kriging on the mesh grid
z, ss = OK.execute('grid', x_coordinates, y_coordinates)
# z contains the interpolated elevation values
# ss is the squared error estimate
# Plotting the result (optional)
plt.imshow(z, extent=(xmin, xmax, ymin, ymax), origin='lower')
plt.scatter(x_known, y_known, c='r') # known points in red
plt.title('Kriging Interpolation of Elevation')
plt.colorbar(label='Elevation')
plt.show()
Lastly, we leverage the Geospatial Data Abstraction Library to export this array as a geoTiff. GeoTiff is a standard format for raster images which includes information about its coordinate system (CRS) the resolution, and the global coordinates of the upper left corner so it can be appropriately mapped to a true location in software like ArcGIS Pro and Google Earth. Note: In the context of GDAL in Python, "OSR" stands for "OGR Spatial Reference" and "OGR" stands for "OpenGIS Simple Features Reference."
For an in-depth dive into Coordinate Systems we also have you covered

import numpy as np
from osgeo import gdal, osr
def export_geotiff(dem_array, output_file, geotransform, spatial_reference):
driver = gdal.GetDriverByName("GTiff")
rows, cols = dem_array.shape
dataset = driver.Create(output_file, cols, rows, 1, gdal.GDT_Float32)
dataset.GetRasterBand(1).WriteArray(dem_array)
dataset.SetGeoTransform(geotransform)
dataset.SetProjection(spatial_reference.ExportToWkt())
dataset.FlushCache() # Write to disk
# Example usage:
# Assuming you have your DEM array named 'dem_array'
# Assuming you have your geotransform and spatial reference prepared
# Replace 'dem_array', 'output_file', 'geotransform', and 'spatial_reference' with your actual data
# Define the output file path
output_file = "output_dem.tif"
# Example geotransform (replace with actual geotransform)
geotransform = (0, 1, 0, 0, 0, 1)
# Example spatial reference (replace with actual spatial reference)
spatial_reference = osr.SpatialReference()
spatial_reference.ImportFromEPSG(4326) # Example: WGS84
# Call the export function
export_geotiff(dem_array, output_file, geotransform, spatial_reference)
Example Real World Discovery Made With a High Quality DEM:
As we explain in this article:

LiDAR technology offers a unique perspective by generating Digital Elevation Models (DEMs) from the final returns of LiDAR data, revealing the underlying terrain without surface cover. This method has proven invaluable not only in archaeology but also in diverse fields of geosciences.
In 2008, a detailed LiDAR scan of Houston, Texas uncovered previously unknown fault lines, such as the Longpoint Fault. While currently inactive, these fault lines present structural challenges to nearby buildings, prompting ongoing monitoring efforts to ensure safety.

LiDAR-derived DEM revealing fault lines beneath the urban landscape of Houston, Texas, providing crucial insights into the region's geological dynamics. Image courtesy of Richard M. Engelkemeir and Shuhab D. Khan, Department of Geosciences, University of Houston (Engelkemeir & Khan, 2008).
This concludes our initial dive into DEMs; I hope you have learned something and if you like this content please like, comment, share, and subscribe! In our next installment, we will discuss leveraging Google Cloud Platform (GCP) to display DEMs in cloud-based applications with GDAL and Google Earth Engine (GEE)!
References
Engelkemeir, R., & Khan, S. (2008). LiDAR mapping of faults in Houston, Texas, USA. Geosphere, 4, 170-182. https://doi.org/10.1130/GES00096
Geostats Guys. (2020, March 13). Data Analytics [Video]. YouTube. Presented by Michael Pyrcz, Professor in the Cockrell School of Engineering and Jackson School of Geosciences at The University of Texas at Austin.
Rahman, M.A., Ahmed, S., & Imam, M. (2020). Rational Way of Estimating Liquefaction Severity: An Implication for Chattogram, the Port City of Bangladesh. Geotechnical and Geological Engineering, 38. https://doi.org/10.1007/s10706-019-01134-2
Safarov, R., Shomanova, Z., Mukanova, R., Nossenko, Y., Alexandru, I., Sviderskiy, A., & Sarova, N. (2019). Design of Neural Network for Forecast Analysis of Elements-Contaminants Distribution on Studied Territories (On Example of Pavlodar City, Kazakhstan). SERIES Chemistry and Technology, 6, 86-98. https://doi.org/10.32014/2019.2518-1491.78
Štular, Benjamin & Eichert, Stefan & Lozić, Edisa. (2021). Airborne LiDAR Point Cloud Processing for Archaeology. Pipeline and QGIS Toolbox. Remote Sensing. 13. 3225. 10.3390/rs13163225.
About the Author
Daniel Rusinek is an expert in LiDAR, geospatial, GPS, and GIS technologies, specializing in driving actionable insights for businesses. With a Master's degree in Geophysics obtained in 2020, Daniel has a proven track record of creating data products for Google and Class I rails, optimizing operations, and driving innovation. He has also contributed to projects with the Earth Science Division of NASA's Goddard Space Flight Center. Passionate about advancing geospatial technology, Daniel actively engages in research to push the boundaries of LiDAR, GPS, and GIS applications.
