
Leveraging GCP's Dataproc and GeoSpark for Scalable LiDAR Analysis: Continued


Building upon our foundational exploration of GCP Dataproc and GeoSpark, as detailed in our previous post, we continue to unravel the complexities of processing dense LiDAR datasets in the cloud. This series aims not only to showcase advanced data engineering techniques but also to create a comprehensive guide for leveraging GCP's powerful cloud services for geospatial analysis. For our previous article see the link below:

From Theory to Practice: Handling LiDAR Data on GCP
In our initial foray into geospatial data analysis with GCP Dataproc and Spark, we laid the groundwork for understanding how these technologies can revolutionize our approach to processing and analyzing spatial data. Continuing on this path, we now delve deeper into the specific challenges and innovative solutions associated with LiDAR data, particularly addressing the practical limitations of implementing ideal buffer management strategies within Spark and GeoSpark.
Adapting to Spark's Constraints with High-Density LiDAR
As highlighted previously, LiDAR's high-density point clouds provide a rich data source for geospatial analysis.

This density creates both opportunities and challenges within the distributed computing environment of Spark on GCP Dataproc. Recognizing the limitations inherent to Spark, we adopt practical and efficient methods to maximize our analysis's accuracy and scalability.
This practical approach underscores our focus on implementing efficient, scalable solutions within the GCP ecosystem. By optimizing spatial partitioning and employing spatial indexing, we aim to enhance the robustness and efficiency of our LiDAR data analyses. Such strategies demonstrate our dedication to utilizing current technologies to their fullest potential, ensuring our projects are well-aligned with the latest developments in geospatial data science.
However, before delving into specific strategies for handling LiDAR data with GeoSpark, it's essential to understand the capabilities this framework brings to the table. GeoSpark extends Apache Spark to cater specifically to spatial data processing, introducing spatial data types, indexes, and operations into the Spark ecosystem. This specialization enables efficient spatial querying, map matching, and join operations, making GeoSpark particularly well-suited for geospatial workflows. By harnessing GeoSpark's capabilities, users can navigate the intricacies of spatial data analysis with confidence, leveraging its advanced functionalities to address the challenges posed by dense LiDAR datasets in the cloud.
Strategic Data Processing on GCP
Optimizing geospatial workflows on GCP involves a deep dive into GeoSpark's functionalities, enabling us to navigate the intricacies of spatial data analysis with confidence. By focusing on achievable strategies within the GCP ecosystem, such as optimizing spatial partitioning and leveraging spatial indexing, we ensure that our LiDAR data analyses are both robust and efficient, paving the way for innovative applications and insights.
GeoSpark's Specialization in Spatial Data: GeoSpark extends Apache Spark to provide a cluster computing system specifically designed for processing large-scale spatial data. It introduces spatial data types, indexes, and operations into the Spark ecosystem, enabling efficient spatial querying, map matching, and join operations. This specialized focus on spatial data makes GeoSpark particularly suited for geospatial workflows, offering functionalities that are not inherently present in general-purpose data processing frameworks like Apache Beam, which underpins Dataflow.
Spatial Indexing and Partitioning: One of the key features of GeoSpark is its support for advanced spatial indexing methods, such as R-trees and Quad-trees, and spatial partitioning strategies. These features are crucial for efficiently processing and analyzing dense LiDAR datasets. Spatial indexing reduces the search space for query operations, significantly speeding up data processing tasks. Meanwhile, spatial partitioning ensures that data is distributed across the cluster in a manner that minimizes network shuffle and maximizes parallel processing efficiency.
Dataproc Advantages Over Dataflow for Spatial Analysis
While Google's Dataflow is also an effective platform for stream and batch data processing, its capabilities in spatial data processing are not as developed as those of GeoSpark. Dataflow excels in handling large-scale data processing workflows, especially when integrated with other GCP services, but it lacks the native support and specialized libraries that GeoSpark offers for spatial data analysis. Furthermore, the Spark ecosystem, accessible through Dataproc, includes a wealth of libraries and tools developed specifically for geospatial workflows.
The Importance of Efficient Spatial Partitioning in GeoSpark
Efficient spatial partitioning is a cornerstone of effective geospatial data processing, especially for applications like Kriging, which relies heavily on neighbor searches to predict values at unknown locations. GeoSpark's use of spatial partitioning strategies, such as quadtrees, plays a pivotal role in enhancing these computations. While the specific implementation details may vary across programming languages and frameworks, the underlying principle remains consistent: breaking the space into manageable chunks to facilitate efficient data indexing and retrieval.
How Quadtrees Optimize Neighbor Searches
Quadtrees divide the dataset into quadrants recursively until each leaf node reaches a specified capacity, effectively breaking down the space into smaller, more manageable chunks. This method allows for efficient indexing through pointers, where each quadrant or leaf node can be quickly accessed and searched. When applied to Kriging, which necessitates extensive neighbor searches to estimate values at unsampled points, quadtrees significantly reduce the computational load.
In a traditional, non-partitioned dataset, finding the closest neighbors to a point for Kriging interpolation would require comparing the target point against every other point in the dataset, leading to a computational complexity of O(n^2). However, with quadtrees, the search space is dramatically reduced. Once the quadrant containing the target point is identified, the algorithm only needs to perform distance calculations within this much smaller subset of points. While the search within a quadrant still exhibits O(n^2) complexity, the "n" in this case is significantly smaller, leading to a substantial reduction in processing time and computational resources.
This video from Trinity University, San Antonio, Department of Computer Science Science gives a great rundown of the concept highly worth a watch!
Why Quadtrees Are Used in GeoSpark
Now quadtrees in GeoSpark work a little differently; they are used primarily for spatial partitioning, not directly for individual point queries or neighbor searches. The purpose of using a quadtree in this context is to divide the entire dataset into smaller, more manageable partitions, which can be processed in parallel. Each partition can be thought of as a bucket that contains a subset of the data, spatially localized to a specific quadrant defined by the quadtree.
How Quadtrees Enhance Efficiency
Parallel Processing: By partitioning the data, GeoSpark can leverage Spark's distributed computing capabilities to process multiple partitions in parallel, significantly speeding up operations like spatial joins, range queries, and aggregations.
Reduced Search Space: For spatial queries, such as range queries, the quadtree structure helps narrow down the search space. Instead of searching the entire dataset, GeoSpark can quickly identify which partitions (quadrants) overlap with the query envelope and only search those, reducing the computational load.
Why This Matters for Geospatial Analysis
This efficient approach to spatial partitioning and neighbor searching is particularly advantageous for performing Kriging over large geospatial datasets, such as those derived from LiDAR. By ensuring that only a relevant subset of points is considered for each interpolation calculation, GeoSpark allows for the practical application of computationally intensive techniques like Kriging at scale. This not only speeds up the processing time but also makes it feasible to derive accurate interpolated surfaces from massive datasets, opening up new possibilities for detailed spatial analysis and modeling.
The Edge Challenge in Segmented Data Analysis
Quadtrees are a method used to divide large spatial datasets into smaller, more manageable sections for analysis. This division helps in processing vast amounts of data more efficiently by focusing computational resources on specific areas of interest. However, this method introduces a potential complication when it comes to points located near the borders of these sections.
Understanding the Boundary Complication
Imagine you're analyzing a large, detailed map cut into smaller pieces for easier handling. If you're trying to understand features or patterns that cross the edges where the pieces meet, you might miss some connections or details that are split across two pieces. In the realm of geospatial analysis, where understanding the full context of data points is crucial for accurate predictions and interpolations, such as with Kriging—a method used to estimate unknown values based on known data points—this "edge" problem can lead to less precise results.
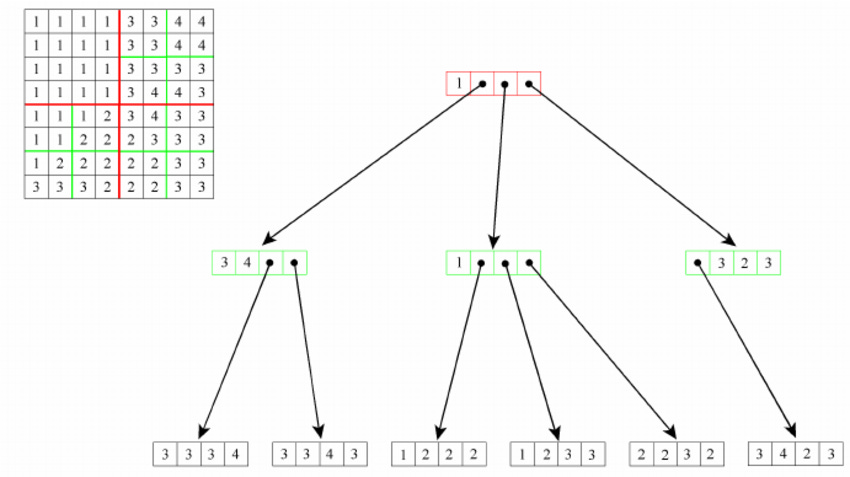
The figure depicts the creation and querying process in a quadtree data structure, which is a tree where each internal node has exactly four children. The creation begins at the root node and recurses down, with each node representing a quadrant of the space, dividing until a base case is reached, usually defined by a lower bound on the number of points within a quadrant. The process of querying for neighbors is complicated when the desired points span across different quadrants (highlighted in red and green). For a query initiated in one quadrant (red), to access data in an adjacent quadrant (green), the algorithm must backtrack to their common ancestor node and then descend into the adjacent quadrant. This demonstrates an inefficiency in the quadtree's design for neighbor queries, as it involves additional upward and downward traversals, which can be computationally expensive, rather than direct lateral movement between neighboring nodes (Dean, 2005).
Specifically, when the area we're interested in, our "search area"for gathering relevant data points to make a prediction, extends across the borders of these sections, we may inadvertently overlook important data points right on the other side of the border. This oversight can affect the accuracy of our predictions, particularly for points near these borders.
However, GeoSpark has some nifty tools to handle this situation!
Local Quadtrees Implementation:
When gridding point data locally the main aim of our quadtree is like above; the improve the efficiency of our search queries when we need to identify neighbors around a point we want to predict. However, there are some distinctions between a traditional local approach and a distributed computing approach in GeoSpark.
Gridding Point Data Locally:
Focus on Search Efficiency: Utilizing a quadtree on a local system primarily aims to boost the efficiency of spatial searches. The quadtree structure localizes searches to specific quadrants, minimizing the number of comparisons required to locate desired data points.
Resource Limitations: Local computing is typically constrained by fixed computational resources. Optimizing search efficiency is crucial to maximizing these limited resources effectively.
Cloud Computing with GeoSpark on GCP Dataproc:
Emphasis on Parallel Processing: GeoSpark, when used within a cloud environment like GCP Dataproc, shifts the focus toward leveraging distributed computing for handling voluminous datasets. Spatial partitioning through quadtrees facilitates this parallel processing across a cluster's multiple nodes.
Scalability and Dynamic Resource Allocation: The cloud offers scalability and the flexibility to allocate resources dynamically, enabling the processing of extensive datasets that would be challenging to handle locally.
Enhanced Efficiency with R-Trees: In each quadrant formed by the quadtree partitioning, GeoSpark can further create R-trees, optimizing spatial searches within those partitions. This additional layer of indexing enhances the efficiency of operations like range queries and spatial joins by organizing data within each partition for rapid access and query execution.
For more on R-Trees see this article by Markus Hubrich:
https://towardsdatascience.com/speed-up-your-geospatial-data-analysis-with-r-trees-4f75abdc6025 (Miller, 2023).
Cost and Performance Optimization: Although cloud resources are expansive, they are not without cost. The ability to scale resources according to demand allows for a balance between performance and expenditure, utilizing the cloud's computational prowess for tasks such as dense LiDAR data processing.
Summary:
The strategic use of quadtrees for spatial partitioning in GeoSpark, coupled with the creation of R-trees within each quadrant, exemplifies the cloud's advantage for geospatial data analysis. This approach not only capitalizes on the cloud's ability to process large datasets through parallel computing but also enhances query efficiency within each partition. The combination of cloud computing's scalability with GeoSpark's spatial data structuring techniques transforms geospatial data analysis, making previously unattainable levels of processing speed and data analysis depth achievable.
Charting the Future of Geospatial Analysis on GCP
As we continue our exploration of geospatial data engineering on GCP, each post in this series builds upon the last, creating a rich repository of knowledge and expertise. Our journey through leveraging GCP's Dataproc and GeoSpark for LiDAR data analysis exemplifies the power of cloud computing in unlocking the potential of spatial data, driving forward the frontiers of environmental monitoring, urban planning, and beyond.
Stay tuned to TechTerrain for more insights, strategies, and code examples as we further explore the capabilities of GCP and GeoSpark. Together, we are shaping the future of geospatial data analysis, one dataset at a time.
Thank you for reading and I hope you’ve learned something… if you like this content please like, comment, share, and subscribe!
References
Data Systems Lab, 2023. GeoSpark documentation. Available at: https://geospark.datasyslab.org/. (Accessed 20 March 2024).
Dean, Denis. (2005). Measuring Arrangement Similarity Between Thematic Raster Databases Using a QuadTree-Based Approach. 3799. 120-136. 10.1007/11586180_9.
Lewis, M. (2013, November 13). Quadtrees. YouTube.
Miller, A. (2023, May 21). Speed Up Your Geospatial Data Analysis with R-trees. Towards Data Science. Retrieved from https://towardsdatascience.com/speed-up-your-geospatial-data-analysis-with-r-trees-4f75abdc6025
About the Author
Daniel Rusinek is an expert in LiDAR, geospatial, GPS, and GIS technologies, specializing in driving actionable insights for businesses. With a Master's degree in Geophysics obtained in 2020, Daniel has a proven track record of creating data products for Google and Class I rails, optimizing operations, and driving innovation. He has also contributed to projects with the Earth Science Division of NASA's Goddard Space Flight Center. Passionate about advancing geospatial technology, Daniel actively engages in research to push the boundaries of LiDAR, GPS, and GIS applications.
