
World Models vs. Kalman Filter
Beyond Surface Comparisons

In the dynamic field of artificial intelligence, new methodologies often prompt comparisons to established techniques. Recently, 'World Models', as introduced by David Ha and Jürgen Schmidhuber, have sparked a debate over their similarity to the Kalman Filter (Goel and Bartlett, 2023; LeCun, 2024). We recently covered some differences between the two in this article:

Critics suggest that World Models merely repurpose existing ideas; But is this criticism justified? Let’s take a closer look!
Understanding the Fundamentals
It's essential to comprehend the foundational aspects of each system:
The Kalman Filter (Kalman, 1960) is a statistical tool designed for linear state estimation in dynamic systems, particularly effective in filtering out noise from measurements for precise state estimations. If you want to learn all the gory details, take a look at this great video series by Michael van Biezen.
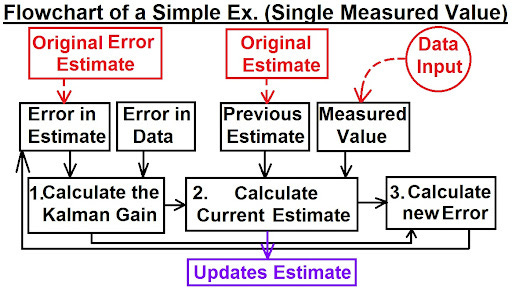
We also have you covered with a great blog post summarizing discussing the Kalman filter as well as some history behind it.

World Models (Ha & Schmidhuber, 2018) on the other hand combines a trio of neural network components:
A Variational Autoencoder (VAE) for data compression.
A Recurrent Neural Network (RNN) for modeling temporal dynamics.
A Controller (C Model) for decision-making.
World ModelMulti-Step Process
The proposed World Model consists of three models:
V model (VAE Transformer)
What is a VAE?: Think of a VAE as a machine that has two main parts:
The Encoder: This part takes in data (like pictures) and compresses it into a simpler form, a set of numbers representing the essence of that data.
The Decoder: This part tries to rebuild the original data from the compressed form.
Training Data: VAEs are trained using a collection of data (like a bunch of pictures) without needing to know what each picture represents (hence, unsupervised learning).
The Training Goal: The aim is to teach the VAE to compress data in such a way that it can be reconstructed back as close to the original as possible.
How Does Training Work?:
Step 1: The encoder takes a piece of data (e.g., an image) and converts it into a simpler, compressed form (a set of numbers).
Step 2: From this compressed form, the VAE randomly picks points that are 'close' to it. This randomness helps the VAE learn to handle a bit of uncertainty and variation, which is important for it to understand the data better.
Step 3: The decoder takes these points and tries to reconstruct the original piece of data from them.
Learning From Mistakes (Loss Function):
The VAE looks at how different the reconstructed data is from the original data. This difference is called the "reconstruction loss."
There's also a check to make sure that the compressed form doesn't stray too far from a 'normal' pattern. This check is called the "regularization term."
Improvement Over Time:
The VAE tries to minimize both the reconstruction loss and the deviation from the 'normal' pattern.
Through many rounds of training with lots of data, the VAE gets better at compressing and reconstructing the data.
Result: After training, the VAE becomes good at taking data, compressing it, and then reconstructing it back with minimal loss. It can even create new data that resembles the original data set.
M Model (MDN-RNN)
The Mixture Density Network with Recurrent Neural Network (MDN-RNN) is a neural network architecture commonly used for modeling sequential data, particularly in the context of probabilistic modeling, such as in time series forecasting or handwriting generation. It combines the strengths of both recurrent neural networks (RNNs) and mixture density networks (MDNs) (Bishop, 1994; Graves, 2013).
Here's a simplified explanation of how the MDN-RNN works:
1. Recurrent Neural Network (RNN) Component
The RNN component processes sequential data inputs. It has recurrent connections that allow it to capture temporal dependencies within the data. At each time step, the RNN takes an input (such as a feature vector representing the data at that time step) and its internal state from the previous time step, and produces an output and an updated internal state (Graves, 2013).
2. Mixture Density Network (MDN) Component
The MDN component predicts the probability distribution of the next value in the sequence given the current input and the RNN's hidden state. Instead of predicting a single deterministic output, the MDN predicts a probability distribution over possible outputs. It models this distribution as a mixture of several probability distributions (typically Gaussian distributions). Each component of the mixture is characterized by its mean, variance, and mixture weight (Bishop, 1994).
3. Combining RNN and MDN
The RNN and MDN components are combined such that the RNN provides context and captures temporal dependencies, while the MDN predicts the probability distribution of the next value in the sequence conditioned on this context. Next, the output of the RNN is used as input to the MDN, along with additional context if needed. The MDN then produces parameters (mean, variance, and mixture weights) of the probability distribution over the next value.
4. Training
During training, the model is trained to maximize the likelihood of observing the actual next value given the input sequence. This involves minimizing a loss function that incorporates both the likelihood of the observed next value under the predicted probability distribution and any regularization terms. The parameters of both the RNN and MDN components are updated using backpropagation through time (BPTT) or another suitable optimization algorithm (Graves, 2013).
5. Inference
During inference, the model can be used to generate predictions for future values in the sequence. At each time step, the model samples from the predicted probability distribution to obtain a stochastic prediction. Alternatively, the model can provide point estimates (e.g., the mean of the distribution) depending on the application's requirements.
Overall, the MDN-RNN architecture allows for flexible and probabilistic modeling of sequential data, making it suitable for various tasks such as time series prediction, language modeling, and handwriting generation (Bishop, 1994; Graves, 2013).
C Model (Controller)
The Controller (C) model plays a pivotal role within the broader framework of reinforcement learning, guiding the agent's actions to maximize the expected cumulative reward during interactions with the environment. In the discussion below, the authors delineate the attributes and operational mechanisms of the Controller model.
1. Purpose of the Controller Model
The primary function of the Controller model is to discern optimal actions for the agent within its environment to maximize cumulative rewards, a fundamental aspect of reinforcement learning (Ha & Schmidhuber, 2018).
2. Simplicity and Separation from Other Models
In experimental settings, deliberate efforts are made to maintain the Controller model's simplicity and size. It is trained independently from other components like the Value (V) and Model (M) models, ensuring that the majority of the agent's complexity resides within the world model (V and M). This strategic decision aims to leverage potential benefits such as computational efficiency, interpretability, and training ease (Ha & Schmidhuber, 2018).
3. Structure of the Controller Model
The Controller model is characterized by its simplicity, manifested in a single-layer linear architecture. At each time step, the Controller integrates two inputs, Zt and Ht likely representing environmental features and internal agent states, respectively. These inputs are linearly transformed to produce the action At, facilitated by the weight matrix Wc and bias vector Bc. Notably, the linear model architecture simplifies the decision-making process (Ha & Schmidhuber, 2018).
4. Parameterization
Essential to the functionality of the Controller model are its parameters, comprising the weight matrix and bias vector. These parameters undergo iterative refinement during the training phase, typically employing optimization techniques such as gradient descent. The overarching objective is to enhance the Controller's decision-making efficacy (Ha & Schmidhuber, 2018).
In summary, the Controller (C) model assumes a critical role in reinforcement learning setups, dictating the agent's actions based on real-time observations and internal states. Its streamlined design, coupled with the segregation from other model components, underscores its significance in optimizing the learning process (Ha & Schmidhuber, 2018).
Putting It All Together
Value Model (V): This model assesses the desirability or expected future rewards associated with different actions or states in the environment. It provides a measure of the value of various actions, helping the agent determine which actions are likely to lead to favorable outcomes.
Model Model (M): The Model model learns and simulates the dynamics of the environment. It predicts future states or observations based on current actions and states. By providing a simulation of the environment's dynamics, the Model model allows the agent to plan and explore potential future scenarios without interacting directly with the environment.
Controller Model (C): The Controller model integrates the information from the Value model and the Model model to make decisions and select actions that maximize the agent's expected cumulative reward. It takes into account the desirability of actions from the Value model and the predicted future states from the Model model to determine the best course of action.

This flowchart, sourced from Ha and Schmidhuber (2018), illustrates the processing of environmental data, such as camera images, within the World Model framework. The flowchart demonstrates how sensory inputs are encoded, simulated, and utilized for decision-making, highlighting the interaction between the agent and its environment.
Together, these models form a comprehensive World Model that enables the agent to learn about its environment and make informed decisions to achieve its goals efficiently. The Value model evaluates actions, the Model model simulates the environment, and the Controller model uses this information to make decisions and take actions, ultimately leading to adaptive behavior in the agent.
Divergent Objectives and Applications
Despite both handling temporal data, their purposes are markedly different.
The Kalman Filter is about precision in estimating the state of a system, commonly used in navigation and tracking.
World Models are more holistic, predicting future states and making decisions based on these predictions. This broader application scope indicates a significant divergence from the Kalman Filter's traditional role.
Training and Data Utilization
A key distinction of World Models lies in their training approach. They can be trained using unlabeled, simulated data. This feature means that, in theory, an autonomous vehicle could be trained within a simulation to handle real-world scenarios, a concept aligning with recent advances in AI and robotics (Sutton & Barto, 2018).
Methodological Differences
Their approaches to data processing and prediction are fundamentally different.
The Kalman Filter operates via linear equations, ideal for linear systems with Gaussian noise.
World Models’ RNN component, which bears some resemblance to the Kalman Filter in its role of handling temporal data, is capable of learning complex, non-linear relationships from data.
Integration of Diverse Data Sources
A World Model, particularly its VAE (Variational Autoencoder) component, could be designed to process and compress high-dimensional data from different sensors into a more manageable form. This would involve encoding data like LiDAR point clouds, camera images, and GPS coordinates into a lower-dimensional latent space.
The key challenge would be to effectively combine these different types of data (which have different characteristics and scales) into a cohesive representation that can be used for further processing and decision-making.
Temporal Dynamics with RNN
The RNN (Recurrent Neural Network) part of the World Model would handle the temporal aspect, learning and predicting how this integrated representation changes over time. This is somewhat analogous to how a Kalman Filter would update its state estimates over time, but with the added capability of handling non-linear dynamics and learning complex patterns from the data.
Decision-Making with the Controller
The Controller component would then use this information to make decisions or predictions, similar to how a decision-making algorithm might use the output of a Kalman Filter. However, the Controller in a World Model would likely be more sophisticated, potentially capable of making complex decisions based on the learned representations and predictions of the environment.
Differences from Kalman Filter
Unlike a Kalman Filter, which is primarily a linear estimator designed for systems with Gaussian noise, a World Model, especially with a VAE and RNN, can handle more complex, non-linear relationships in the data. This makes it potentially more powerful for certain applications, especially those involving complex sensory data and environments.
Application in Robotics and Autonomous Systems
Such an implementation of World Models could be particularly useful in robotics and autonomous vehicle systems, where integrating and interpreting data from multiple sensors is crucial for navigation and interaction with the environment.
Innovation or Mere Reinvention?
Critics who view World Models as a reiteration of the Kalman Filter might be missing the forest for the trees. The innovative leap in World Models lies in their composite structure, particularly in how the VAE and C model contribute to environmental interaction and decision-making.
Conclusion
Both the Kalman Filter and World Models play distinct roles in the technological landscape. World Models represent a significant step forward in AI methodologies, offering capabilities to tackle complex, non-linear environments - a feat that the Kalman Filter, with its focus on linear dynamics and noise reduction, isn't designed for.
References
Ha, D., & Schmidhuber, J. (2018). World Models. *arXiv preprint arXiv:1803.10122*. Retrieved from https://arxiv.org/abs/1803.10122
Kalman, R. E. (1960). A New Approach to Linear Filtering and Prediction Problems. Journal of Basic Engineering, 82(1), 35-45. doi:10.1115/1.3662552
Goel, G., & Bartlett, P. (2023, December 12). Can a Transformer Represent a Kalman Filter? arXiv preprint arXiv:2312.06937 [cs.LG]. Retrieved from https://arxiv.org/abs/2312.06937
LeCun, Y. (2024, February 23). Lots of confusion about what a "world model" is... [LinkedIn post]. LinkedIn. https://www.linkedin.com/posts/yann-lecun_lots-of-confusion-about-what-a-world-model-activity-7165738293223931904-vdgR/
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
van Biezen, M. (Uploader). (n.d.). Special Topics - The Kalman Filter [Video playlist]. YouTube.
About the Author
Daniel Rusinek is an expert in LiDAR, geospatial, GPS, and GIS technologies, specializing in driving actionable insights for businesses. With a Master's degree in Geophysics obtained in 2020, Daniel has a proven track record of creating data products for Google and Class I rails, optimizing operations, and driving innovation. He has also contributed to projects with the Earth Science Division of NASA's Goddard Space Flight Center. Passionate about advancing geospatial technology, Daniel actively engages in research to push the boundaries of LiDAR, GPS, and GIS applications.
